Update 2: 18th October 2005
Since this was published as a bug report on QuirksMode1 many commenters have pointed out that I got it wrong due to a misunderstanding of the XHTML spec. Having been pointed in the right direction by you all, I think I now understand the problem thanks. My original test page2 is served with a Content-Type HTTP response header of "text/html". According to section 5.1 of the XHTML 1.0 Recommmendation3:
XHTML Documents which follow the guidelines set forth in Appendix C, "HTML Compatibility Guidelines" may be labeled with the Internet Media Type "text/html" RFC2854, as they are compatible with most HTML browsers
So I'd have to follow the guidelines given in Appendix C, or a conforming browser could justifiably be upset. Now section C.34 says:
Given an empty instance of an element whose content model is not EMPTY (for example, an empty title or paragraph) do not use the minimized form (e.g. use <p> </p> and not <p />).
And of course, according to the DTD5 used by my test page, a div element does not have a content model that is EMPTY. So indeed, the browsers get justifiably upset.
However, section 5.1 of the spec3 seems to say it would be acceptable to use the minimized form of the empty div element if I served my page with a Content-Type HTTP response header of "application/xhtml+xml":
Those documents, and any other document conforming to this specification, may also be labeled with the Internet Media Type "application/xhtml+xml" as defined in RFC3236.
So I have an identical copy of my test page served as "application/xhtml+xml"6 which demonstrates that the "bug" does indeed vanish in FireFox and Opera when served like this. Unfortunately, the page cannot be viewed by IE6 when served with this MIME type. Instead, IE provides a "File download" dialog7 instead of rendering the page.
{kind=link}
Which I suppose boils this page down to:
Don't use the minimized form of an empty div element because you have to serve your page as "text/html" in order to keep IE happy
My original post follows.
Update: 18th October 2005
Created a more concise test page2 and submitted a bug report to QuirksMode8 where it has now been published1 in the bug reports list. Thanks to Peter-Paul Koch for maintaining such an excellent resource.
How many childNodes does an empty div element have?
Or to put it more explicitly:
Given this snippet of valid9 markup taken from a valid9 XHTML page...
<div id="test" /> |
...what does this javascript statement evaluate as?
document.getElementById('test').childNodes.length; |
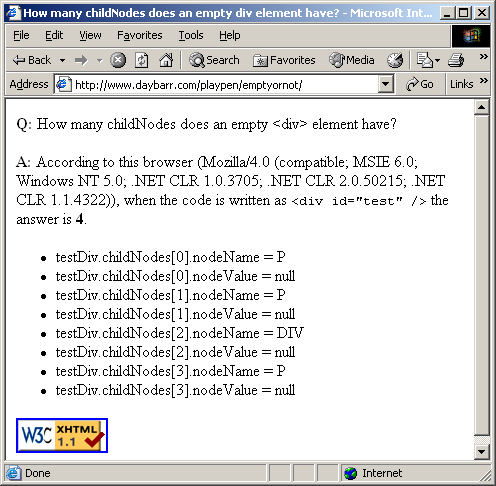
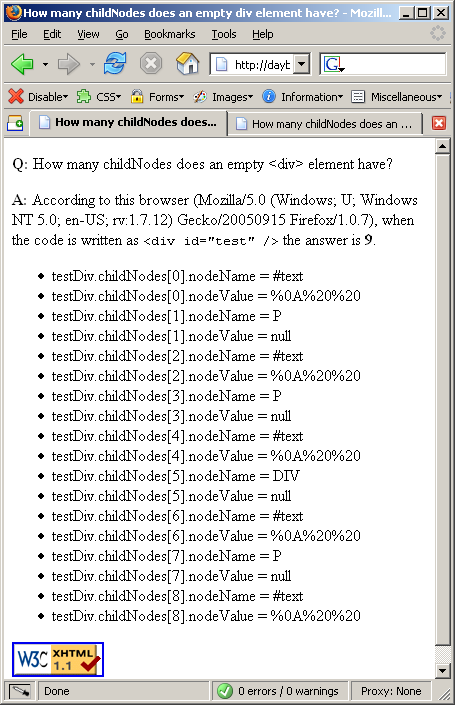
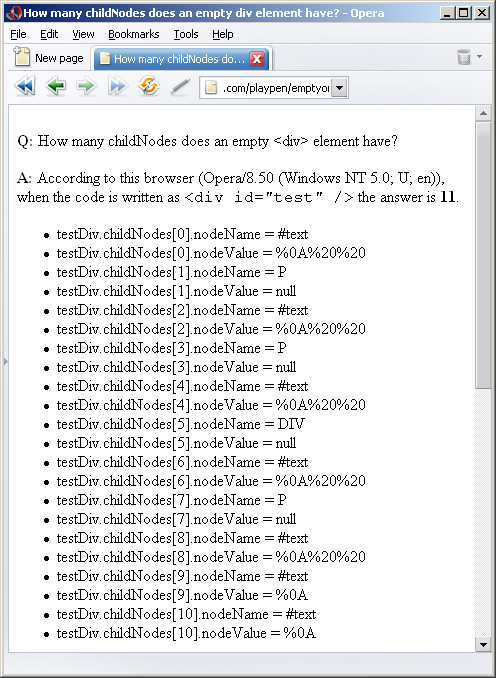
I would expect most rational people to say 0. But most rational people would be wrong just like I was. The answer is actually 4. Or 9. Or 11. As you can see here10, here11 and here12. Try it for yourself by viewing the test page13
{kind=link}
{kind=link}
{kind=link}
Odd. It seems that the various different browsers are actually mistaking childNodes of the test div with the childNodes of the body as we can see from the output of the test page when it dumps the content of the testDiv.childNodes array. The various different answers are as a result of differences between the handling of text nodes by the different browsers. IE doesn't seem to have any text nodes at all in its childNodes array; Opera has 2 line feeds more than Firefox does at the end of its array.
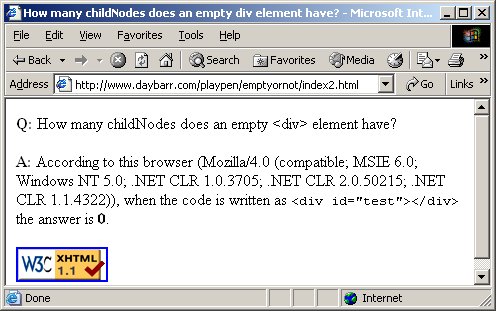
There is a simple workaround for this quirk. For a mere 4 extra bytes we can write the empty div the long way like so.
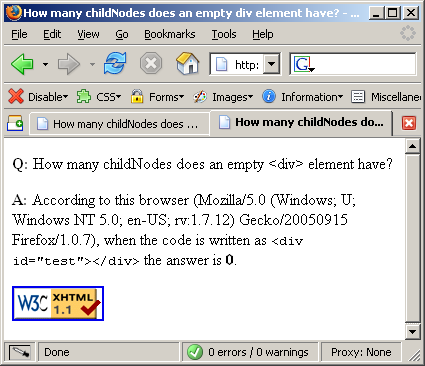
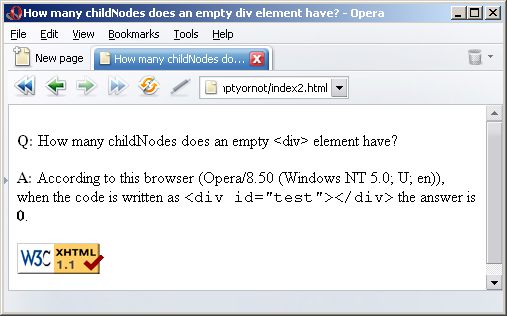
<div id="test"></div> |
Now the browsers all agree with most rational people. Which makes a nice change. You can see the results here14, here15 and here16. Try it for yourself by viewing the test page17.
{kind=link}
{kind=link}
{kind=link}
3 comments
Your test page is being served as "text/html" so it's being rendered as HTML -- hence the behaviour. If you serve it as "application/xhtml+xml" your so called "bug" will probibly go away.
Your page is not valid, and the "bug" non-existant. You are sending XHTML 1.1 as text/html, which is invalid as XHTML 1.1 lacks the famous appendix C. Also, your XHTML, even if it were 1.0, still wouldn't follow the appendix C (empty elements in short form are forbidden unless they're defined as empty in HTML 4.01, like br) and thus proper browser behaviour is not to be expected.
Your markup is treated by browsers as broken HTML, not valid XHTML. Thus the div is treated as unclosed.
As the first comment on QuirksMode says, send the page as application/xhtml+xml (or even application/xml) and it will work fine.
Ah everyone is right of course, but as I have commented on QuirksMode...
Firefox and Opera behave correctly when rendering Krijn's version of the page, which is exactly the same as mine in content but served using the correct MIME type. However, IE 6 cannot view a page that is served with a MIME type of "application/xhtml+xml". Krijn's test page (http://ktk.xs4all.nl/stuff/xhtml/empty-or-not/19 ) uses the HTTP response header "Content-Type: application/xhtml+xml; charset=utf-8" but this causes IE 6 to offer the "File download" dialog instead of rendering the page. Screenshot at http://daybarr.com/playpen/emptyornot/ie6xhtmlmime.jpg20 So this MIME type fix cannot be applied without breaking the page for IE users?
Leave a comment